Model Training 🧠
Word count
784 words
Reading time
5 minutes
Based on the GPTSoVITS base model, fine-tuning training and inference.
Use Cases
If a 3–6 second voice sample cannot meet your cloning needs, you can try training a model to improve voice similarity and realism.
Application Preview
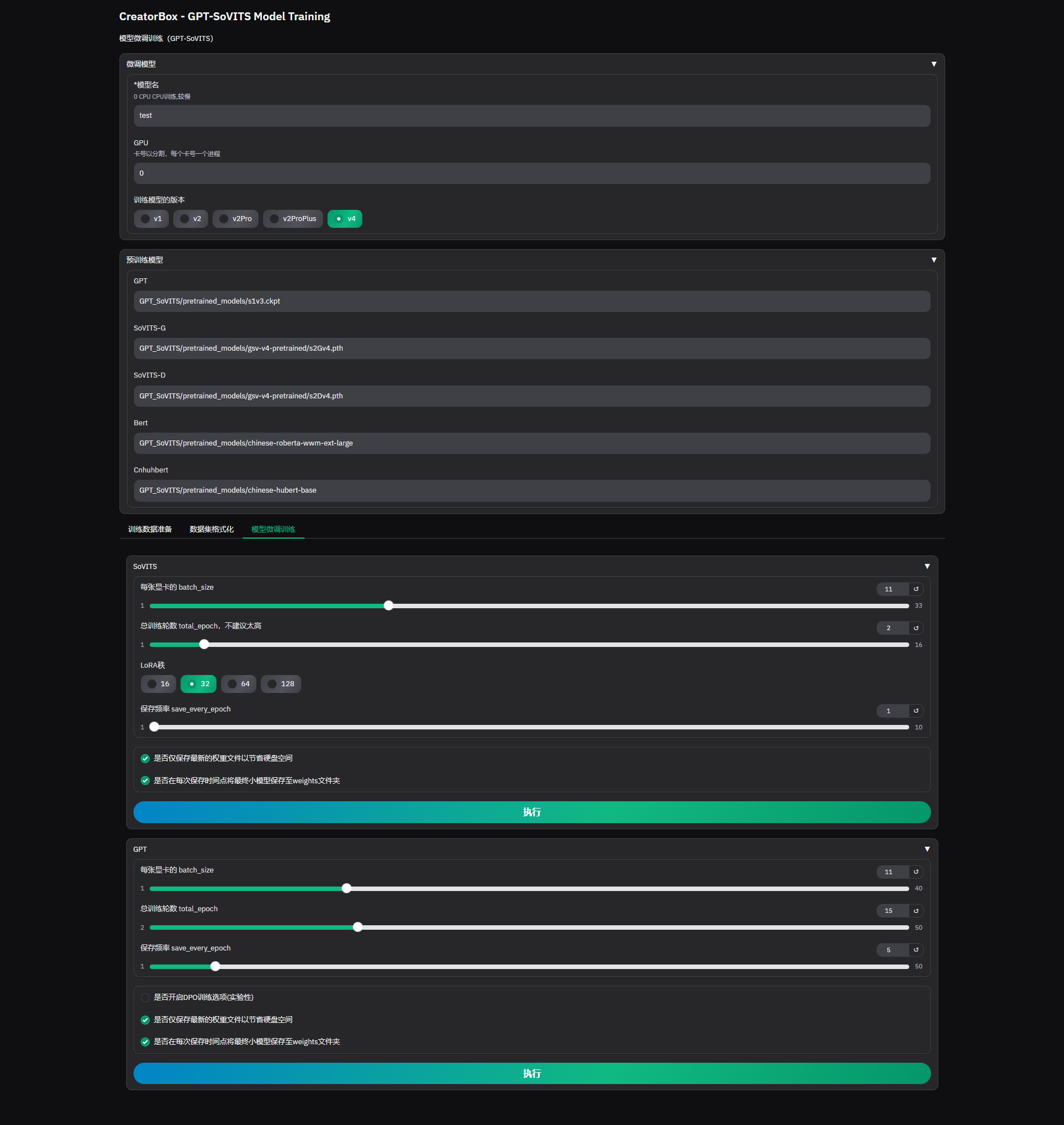
Fine-tuning Training
Please carefully prepare the dataset. A good dataset is the foundation of a good model.
1. Training Data Preparation
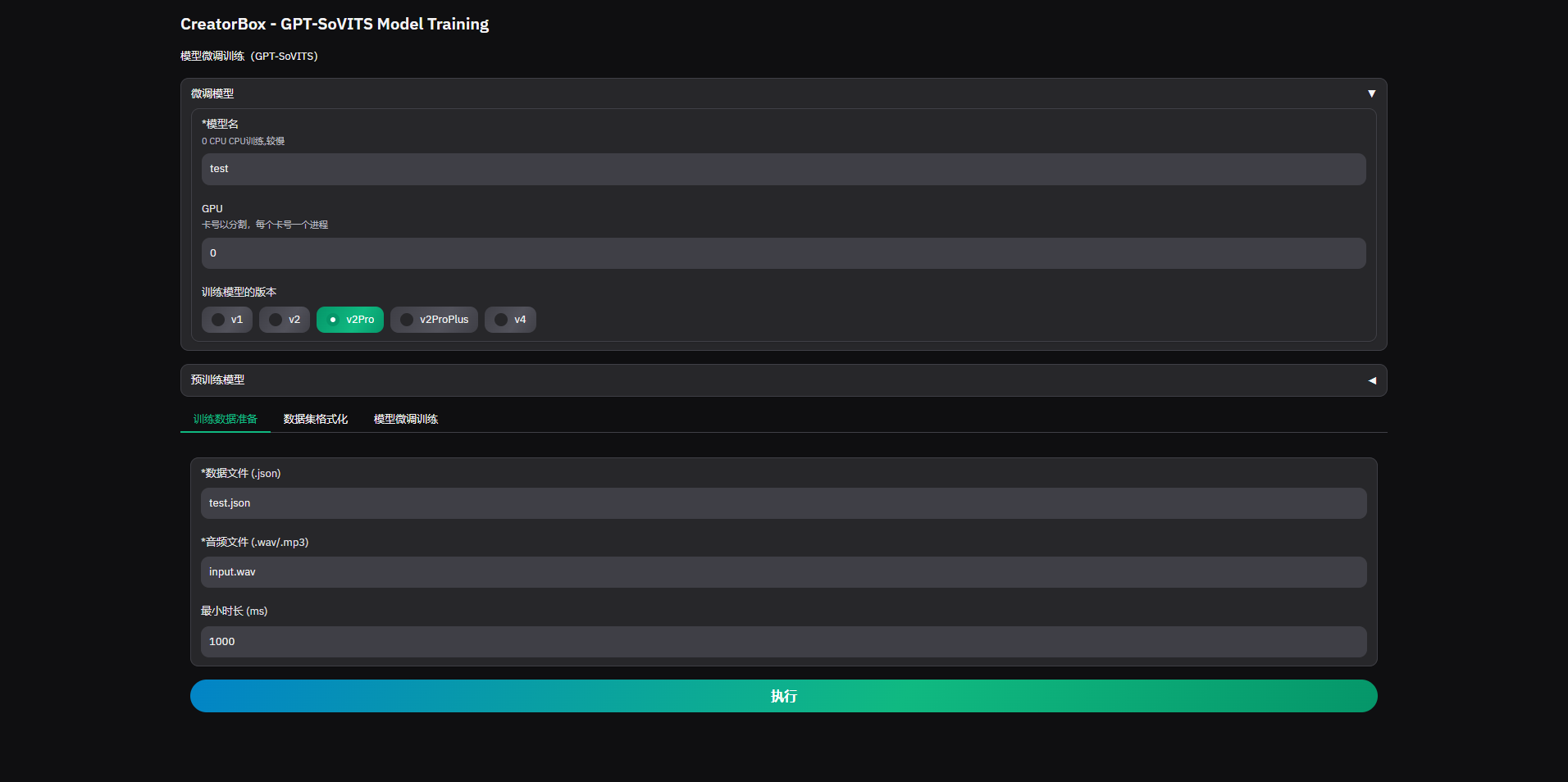
2. Dataset Formatting
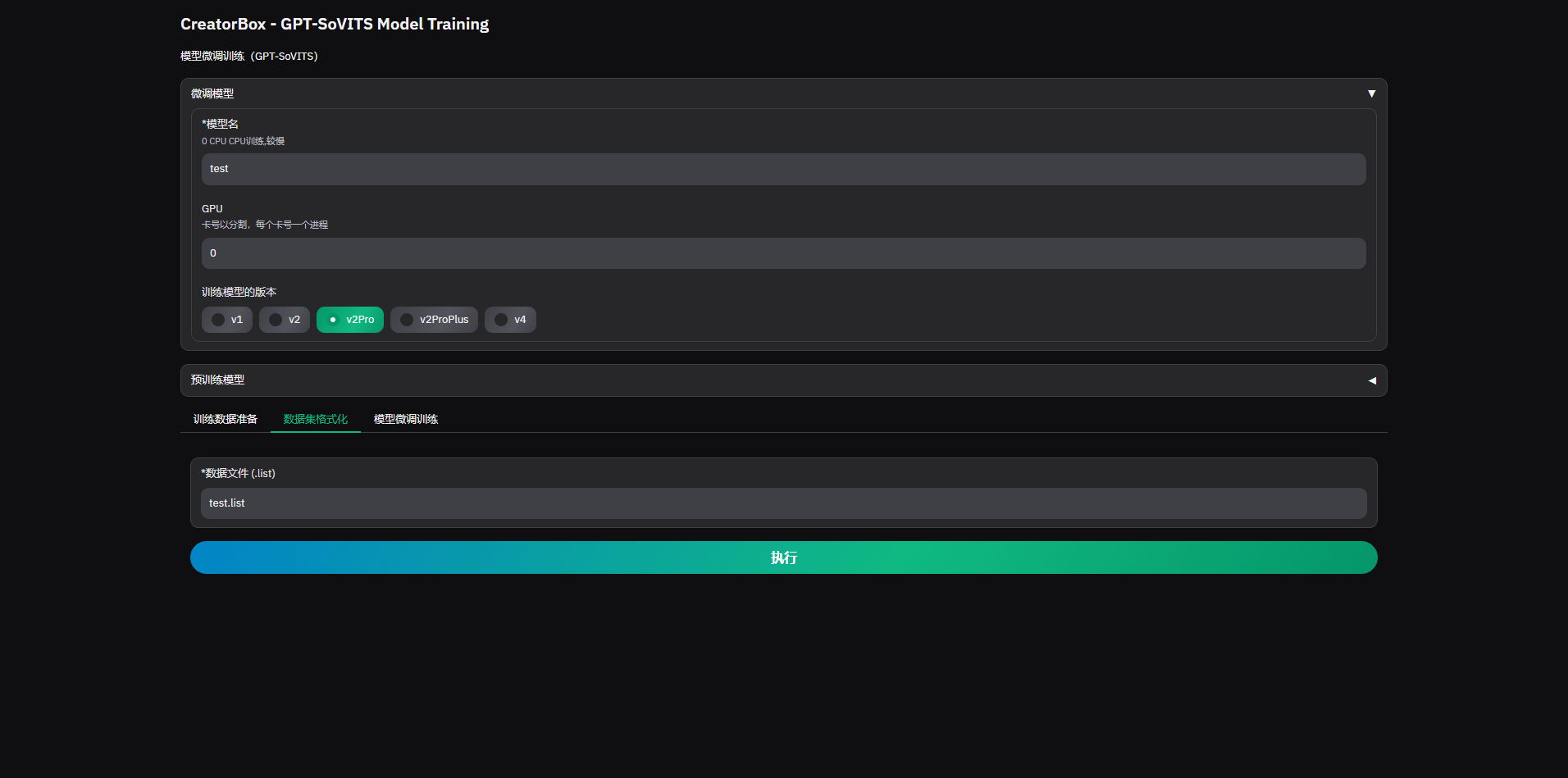
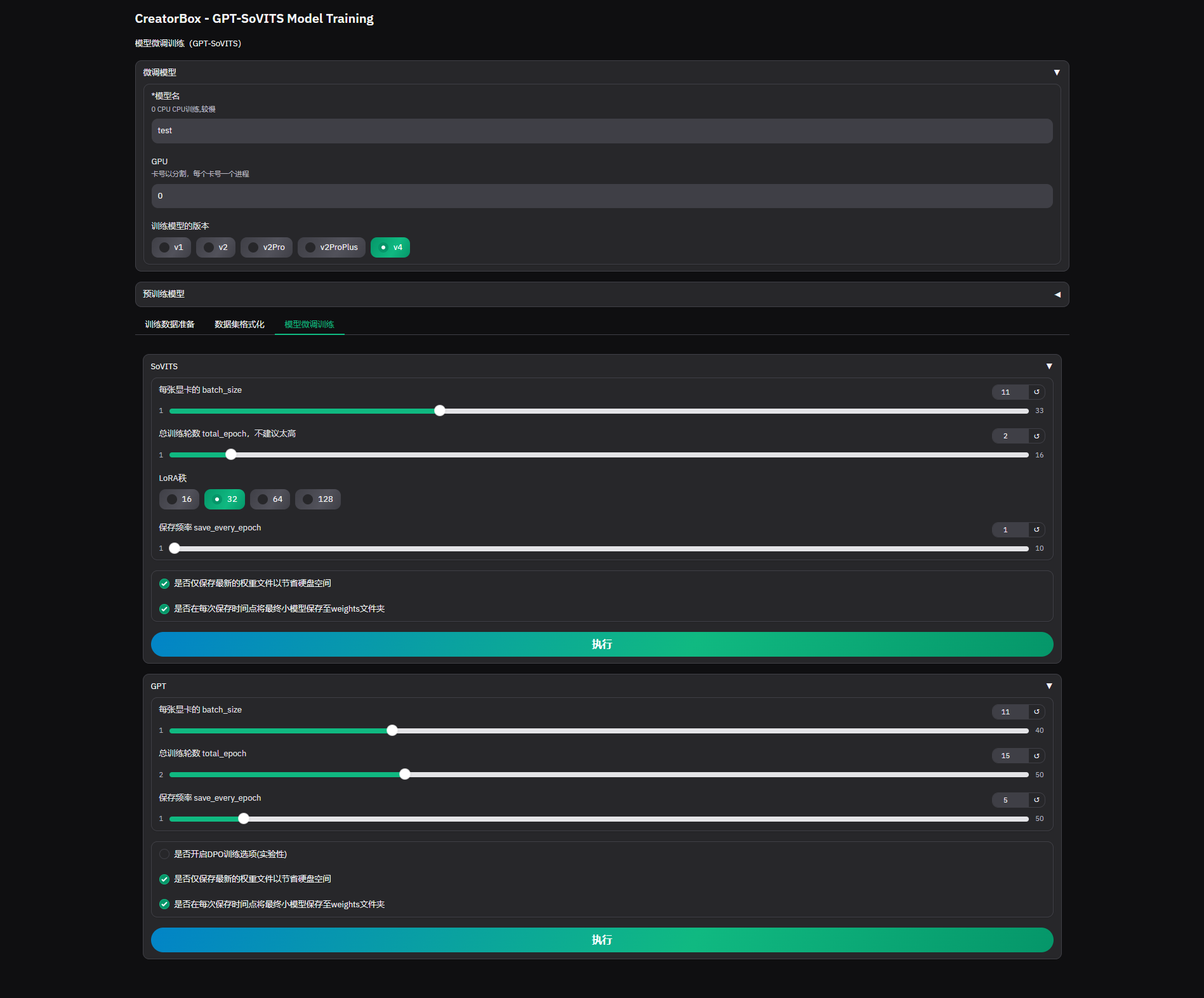
3. Model Fine-tuning Training
Inference Usage
What if you use a fine-tuned model?
1. Configuration Instructions
json
{
"v1": [],
"v2": [],
"v2Pro": [],
"v2ProPlus": [],
"v3": [],
"v4": [
{
"name": "Doctor Genshin",
"gender": "Male",
"locale": "zh-CN",
"model": { // Fine-tuned model directory (required, absolute path)
"default": {
"gpt": "DoctorGenshin-e10.ckpt",
"vits": "DoctorGenshin_e10_s140_l32.pth"
}
},
"ref": { // Main reference audio (corresponding to speaker library ID)
"default": 10000000,
"happy": 10000001,
"sad": 10000002,
"angry": 10000003
},
"aux": [ // Auxiliary reference audio list (optional, absolute path)
"aux_ref_audio_path1.wav",
"aux_ref_audio_path2.wav",
"aux_ref_audio_path3.wav"
]
}
]
}How to control emotions?
Currently, there are two methods: different configurations lead to different results. Choose according to your needs. take happy as an example:
- General-purpose: The training data for a character includes but is not limited to
happy - Customized: The training data for a character only includes
happy
json
{
"name": "Doctor Genshin",
"gender": "Male",
"locale": "zh-CN",
"model": {
"default": {
"gpt": "DoctorGenshin-e10.ckpt",
"vits": "DoctorGenshin_e10_s140_l32.pth"
},
"happy": {
"gpt": "DoctorGenshin_happy-e10.ckpt",
"vits": "DoctorGenshin_happy_e10_s140_l32.pth"
}
},
"ref": {
"default": 10000000,
"happy": 10000001,
"sad": 10000002,
"angry": 10000003
}
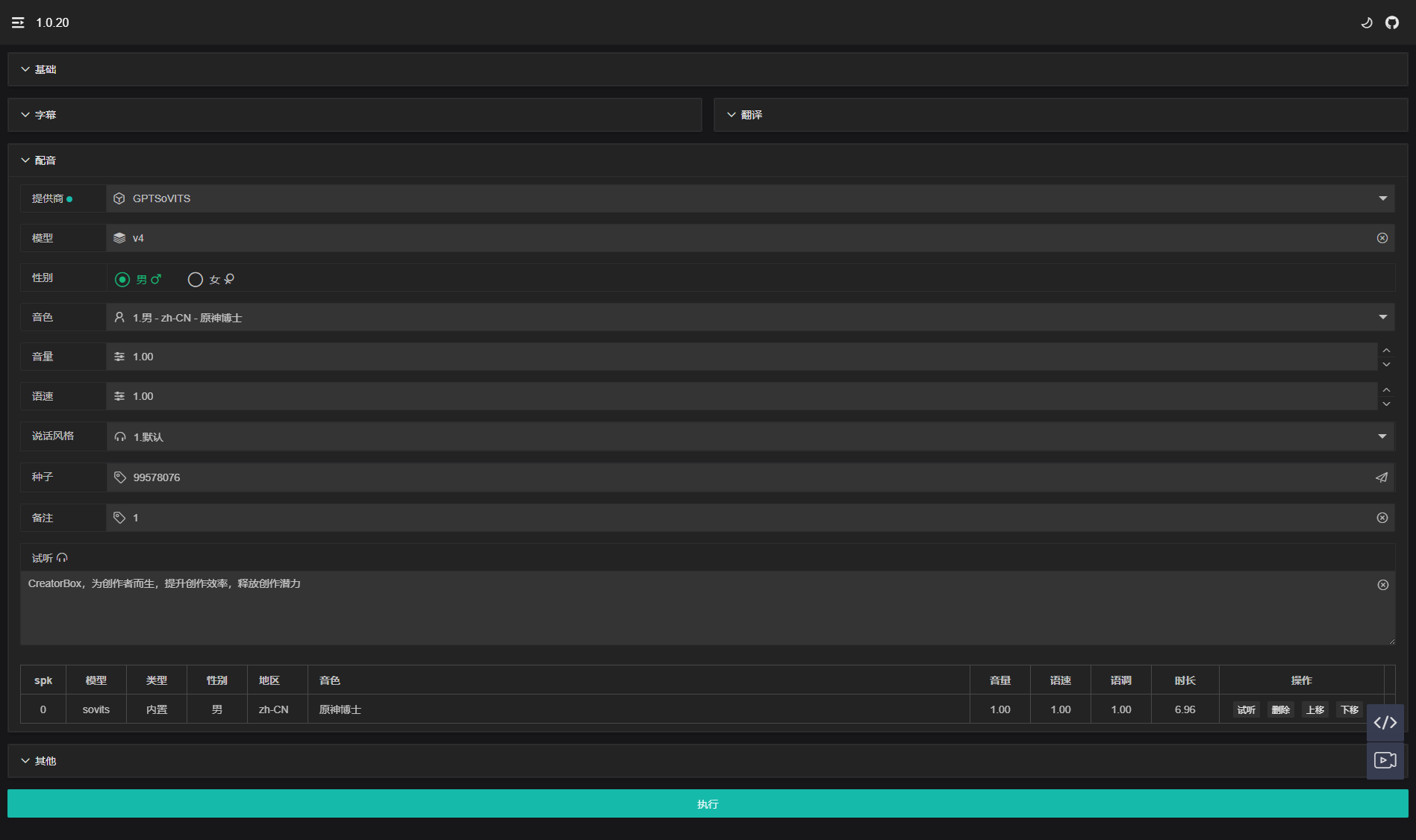
}2. Page Selection
If no model is configured, then the speaking style will not have the
defaultoption, and the timbre will not have theDoctor Genshinoption. At this time, if you select another timbre option and continue inference, the base model will be used for timbre cloning.
2. Runtime Log
log
2025-09-17 14:34:31.336 | INFO 14272 gptsovits_tts.py:72 - First load, please wait...
2025-09-17 14:34:31.338 | INFO 14272 gptsovits_tts.py:78 - Loading Tts model v4 on device cpu
2025-09-17 14:34:31.348 | INFO 14272 TTS.py:589 - Loading Text2Semantic weights from D:/pretrained_models/s1v3.ckpt
2025-09-17 14:34:32.920 | INFO 14272 TTS.py:651 - loading vocoder
2025-09-17 14:34:32.987 | INFO 14272 TTS.py:556 - Loading VITS weights from D:/pretrained_models/gsv-v4-pretrained/s2Gv4.pth. <All keys matched successfully>
2025-09-17 14:34:33.006 | INFO 14272 TTS.py:479 - Loading BERT weights from D:/pretrained_models/chinese-roberta-wwm-ext-large
2025-09-17 14:34:33.478 | INFO 14272 TTS.py:471 - Loading CNHuBERT weights from D:/pretrained_models/chinese-hubert-base
<!-- The custom model will output as follows -->
2025-09-17 14:41:05.508 | INFO 2880 TTS.py:589 - Loading Text2Semantic weights from D:/models/creatorbox/gmt/v4/原神博士/原神博士-e10.ckpt
2025-09-17 14:41:06.913 | INFO 2880 TTS.py:560 - Loading VITS pretrained weights from D:/models/creatorbox/gmt/v4/原神博士/原神博士_e10_s140_l32.pth. <All keys matched successfully>
2025-09-17 14:41:07.097 | INFO 2880 TTS.py:571 - Loading LoRA weights from D:/models/creatorbox/gmt/v4/原神博士/原神博士_e10_s140_l32.pth. _IncompatibleKeys(missing_keys=['enc_p.ssl_proj.weight', 'enc_p.ssl_proj.bias', ....])
2025-09-17 14:34:33.648 | INFO 14272 cache.py:67 - {'v4': {'last_used': '2025-09-17 14:34:33', 'usage': 1},'v4-原神博士-默认': {'last_used': '2025-09-17 14:36:25', 'usage': 1}}
2025-09-17 14:34:33.649 | INFO 14272 TTS.py:197 - Set seed to 99578076
2025-09-17 14:34:33.652 | INFO 14272 TTS.py:1046 - Parallel Inference Mode Enabled
2025-09-17 14:34:33.652 | INFO 14272 TTS.py:1064 - When parallel inference mode is enabled, SoVITS V3/4 models do not support bucket processing; bucket processing has been automatically disabled.
2025-09-17 14:34:34.676 | INFO 14272 TTS.py:1118 - Actual Input Reference Text:
2025-09-17 14:34:35.826 | INFO 14272 TextPreprocessor.py:61 - ############ Segment Text ############
2025-09-17 14:34:35.827 | INFO 14272 TextPreprocessor.py:84 - Actual Input Target Text:
2025-09-17 14:34:35.827 | INFO 14272 TextPreprocessor.py:85 - CreatorBox,为创作者而生,提升创作效率,释放创作潜力.
2025-09-17 14:34:35.828 | INFO 14272 TextPreprocessor.py:114 - Actual Input Target Text (after sentence segmentation):
2025-09-17 14:34:35.829 | INFO 14272 TextPreprocessor.py:115 - ['CreatorBox,', '为创作者而生,', '提升创作效率,', '释放创作潜力.']
2025-09-17 14:34:35.829 | INFO 14272 TextPreprocessor.py:65 - ############ Extract Text BERT Features ############
<!-- Parallel processing,omitted -->
2025-09-17 14:34:40.471 | INFO 14272 TTS.py:1187 - ############ Inference ############
2025-09-17 14:34:40.471 | INFO 14272 TTS.py:1209 - Processed text from the frontend (per sentence):
2025-09-17 14:34:40.471 | INFO 14272 TTS.py:1217 - ############ Predict Semantic Token ############
2%|████ | 29/1500 [00:00<00:19, 75.04it/s]T2S Decoding EOS [141 -> 176]
2%|████▊ | 34/1500 [00:00<00:21, 68.26it/s]
<!-- ..... -->
2025-09-17 14:35:50.402 | INFO 14272 TTS.py:1258 - ############ Synthesize Audio ############
2025-09-17 14:35:50.402 | INFO 14272 TTS.py:1305 - Parallel Synthesis in Progress...
2025-09-17 14:36:18.686 | INFO 14272 TTS.py:1342 - 2.173 4.645 2.194 96.021
2025-09-17 14:36:18.688 | INFO 14272 gptsovits_tts.py:195 - speech len 6.96, rtf 15.091852826633673
2025-09-17 14:36:18.864 | INFO 14272 response.py:52 - {"path":"webapp/tts/sovits_zh-CN_原神博士_1.00_1.00_1.00_32_0.wav","duration":6.96,"seed":99578076}