Model Training 🧠
字数
979 字
阅读
5 分钟
基于 GPTSoVITS 基准模型,微调训练与推理
使用场景
如果3-6秒的声音样本无法满足你的克隆需求,可以尝试训练模型, 提升声音相似度和真实感;
应用预览
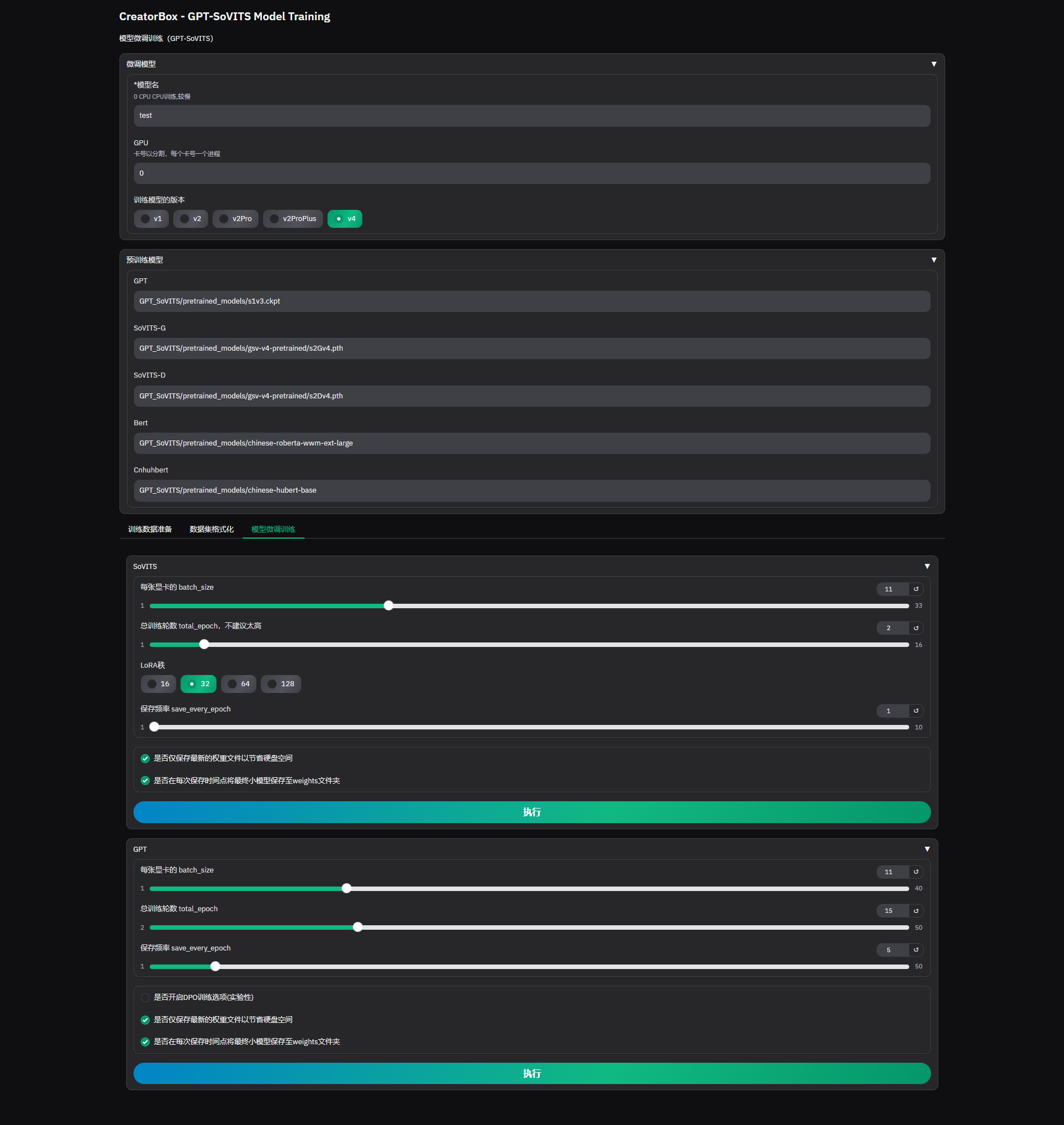
微调训练
请认真准备数据集,好的数据集是炼出好的模型的基础。
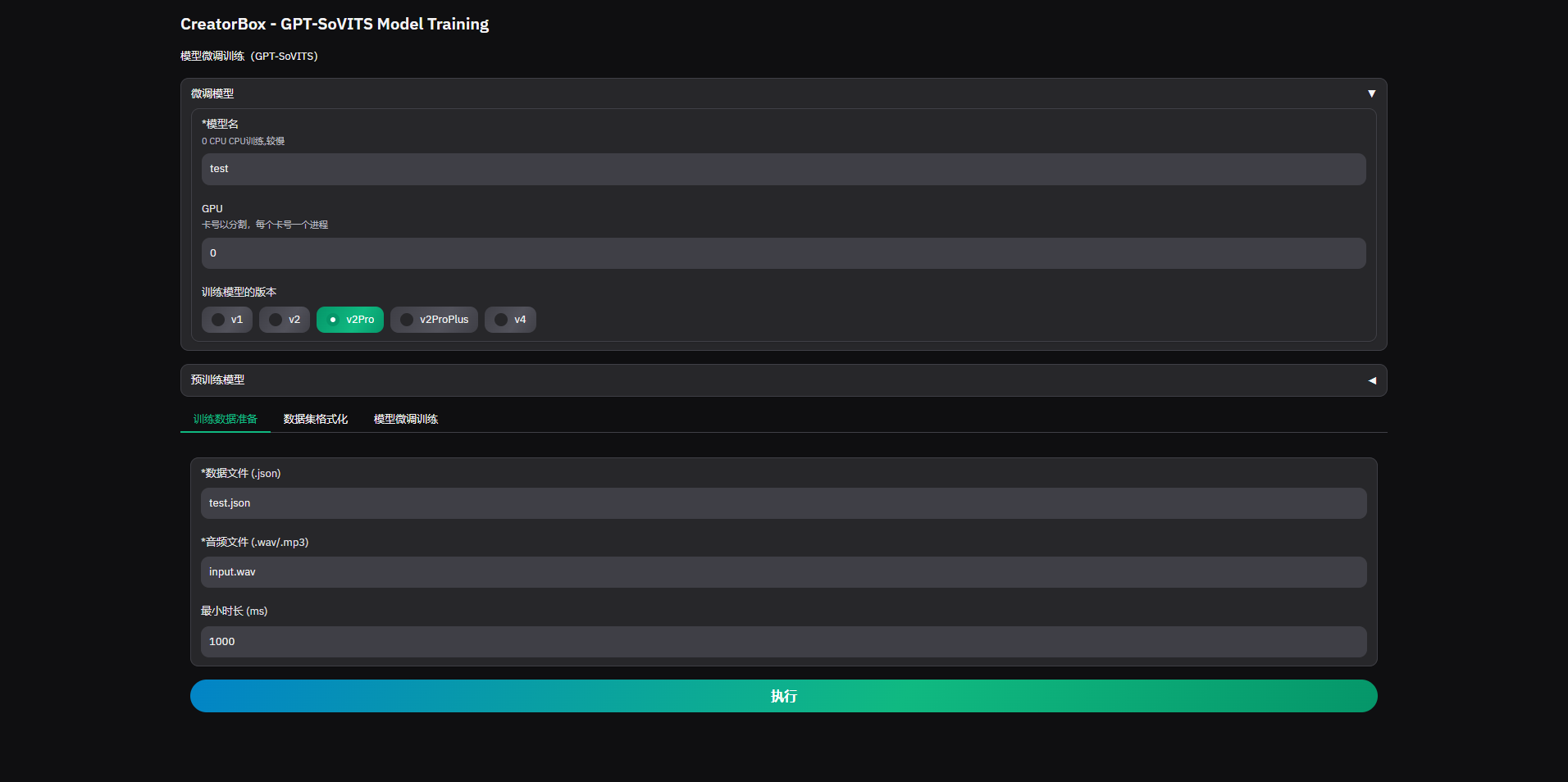
1. 训练数据准备
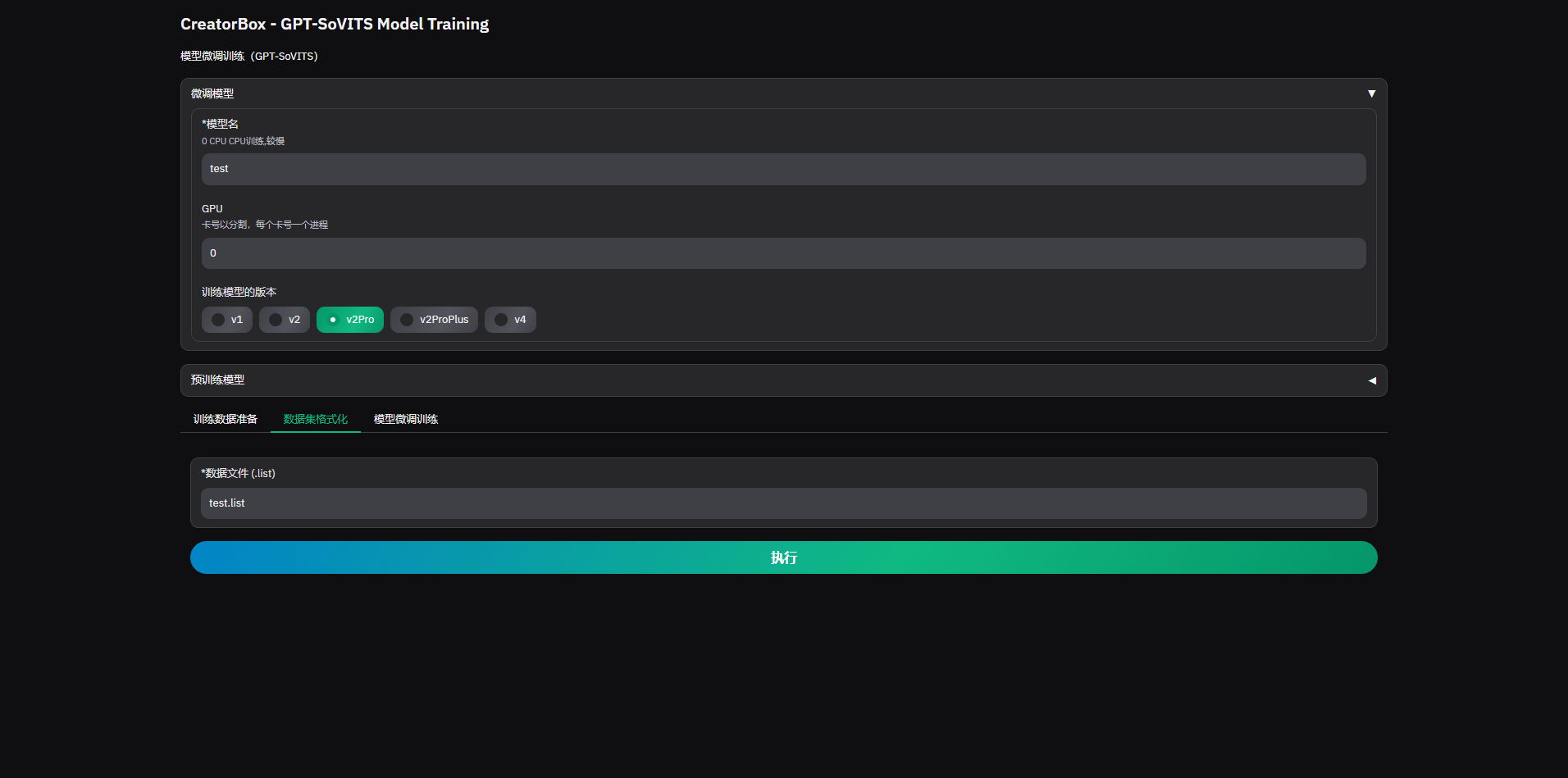
2. 数据集格式化
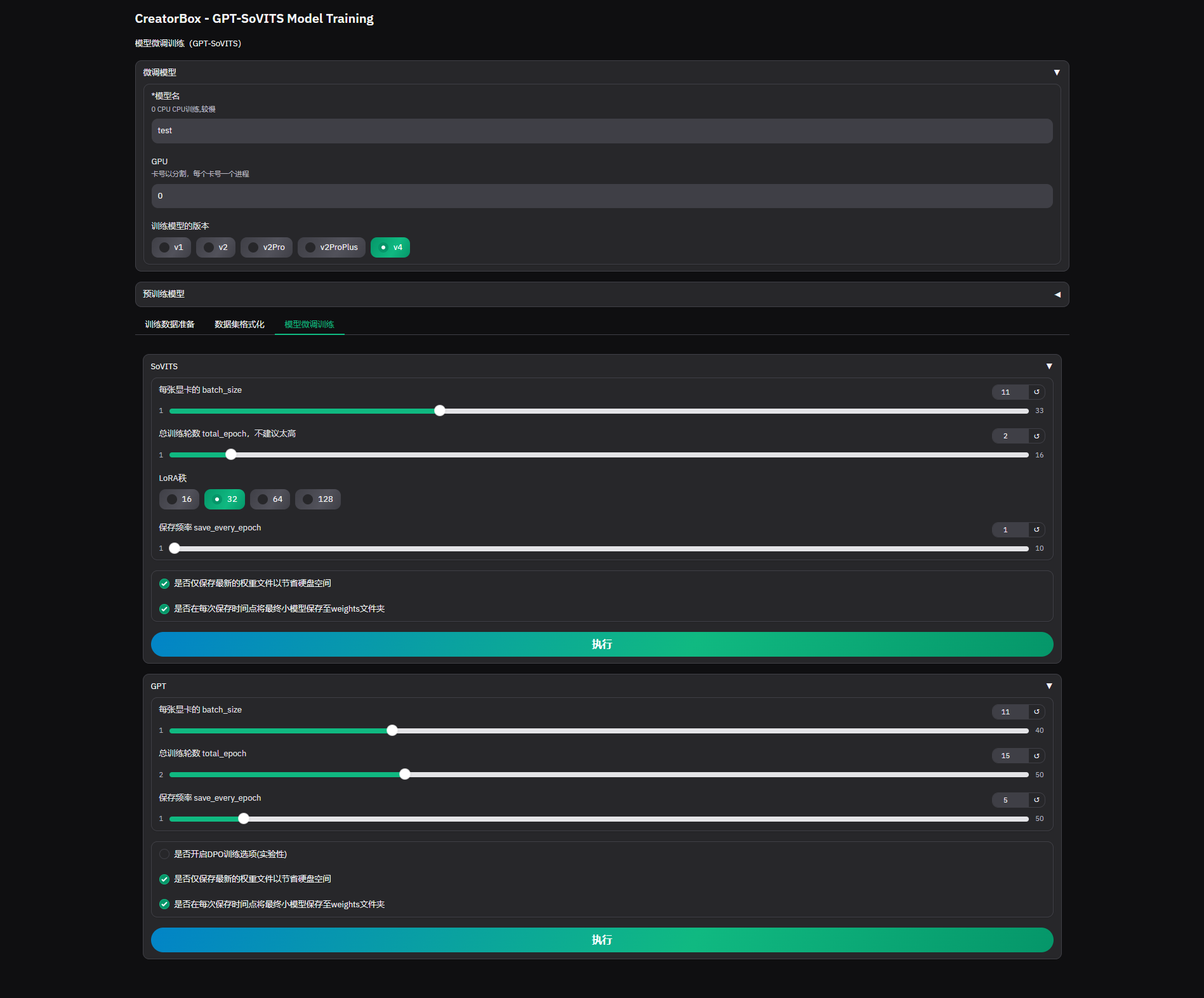
3. 模型微调训练
推理使用
如果使用微调训练的模型?
1. 配置说明
json
{
"v1": [],
"v2": [],
"v2Pro": [],
"v2ProPlus": [],
"v3": [],
"v4": [
{
"name": "原神博士",
"gender": "Male",
"locale": "zh-CN",
"model": { // 微调模型目录(必填,绝对路径)
"默认": {
"gpt": "原神博士-e10.ckpt",
"vits": "原神博士_e10_s140_l32.pth"
}
},
"ref": { // 主参考音频(对应音色库id)
"默认": 10000000,
"高兴": 10000001,
"难过": 10000002,
"生气": 10000003
},
"aux": [ // 辅助参考音频列表(选填,绝对路径)
"aux_ref_audio_path1.wav",
"aux_ref_audio_path2.wav",
"aux_ref_audio_path3.wav"
]
}
]
}如何控制情感?
目前2种方法:配置不同,效果不同,按需取舍;以 高兴 为例:
- 通用型: 某角色训练数据包含但不限于
高兴 - 定制型: 某角色训练数据只包含
高兴
json
{
"name": "原神博士",
"gender": "Male",
"locale": "zh-CN",
"model": {
"默认": {
"gpt": "原神博士-e10.ckpt",
"vits": "原神博士_e10_s140_l32.pth"
},
"高兴": {
"gpt": "原神博士_happy-e10.ckpt",
"vits": "原神博士_happy_e10_s140_l32.pth"
}
},
"ref": {
"默认": 10000000,
"高兴": 10000001,
"难过": 10000002,
"生气": 10000003
}
}2. 页面选择
没有配置模型,此时说话风格无
默认选项,音色也无原神博士选项,此时音色选择其他选项,继续推理会使用底模进行音色克隆
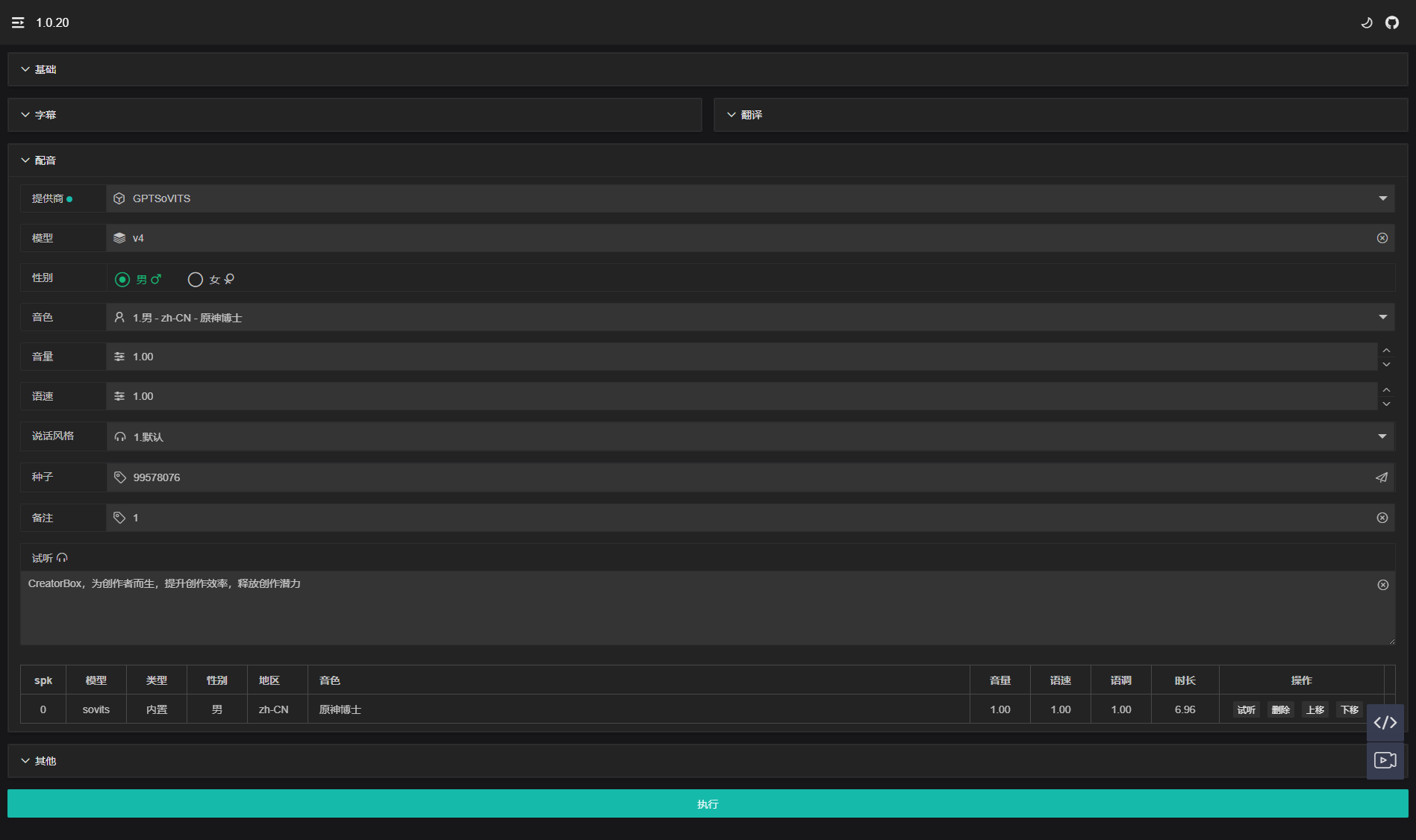
2. 运行日志
log
2025-09-17 14:34:31.336 | INFO 14272 gptsovits_tts.py:72 - First load, please wait...
2025-09-17 14:34:31.338 | INFO 14272 gptsovits_tts.py:78 - Loading Tts model v4 on device cpu
2025-09-17 14:34:31.348 | INFO 14272 TTS.py:589 - Loading Text2Semantic weights from D:/pretrained_models/s1v3.ckpt
2025-09-17 14:34:32.920 | INFO 14272 TTS.py:651 - loading vocoder
2025-09-17 14:34:32.987 | INFO 14272 TTS.py:556 - Loading VITS weights from D:/pretrained_models/gsv-v4-pretrained/s2Gv4.pth. <All keys matched successfully>
2025-09-17 14:34:33.006 | INFO 14272 TTS.py:479 - Loading BERT weights from D:/pretrained_models/chinese-roberta-wwm-ext-large
2025-09-17 14:34:33.478 | INFO 14272 TTS.py:471 - Loading CNHuBERT weights from D:/pretrained_models/chinese-hubert-base
<!-- 自定义模型会打印如下 -->
2025-09-17 14:41:05.508 | INFO 2880 TTS.py:589 - Loading Text2Semantic weights from D:/models/creatorbox/gmt/v4/原神博士/原神博士-e10.ckpt
2025-09-17 14:41:06.913 | INFO 2880 TTS.py:560 - Loading VITS pretrained weights from D:/models/creatorbox/gmt/v4/原神博士/原神博士_e10_s140_l32.pth. <All keys matched successfully>
2025-09-17 14:41:07.097 | INFO 2880 TTS.py:571 - Loading LoRA weights from D:/models/creatorbox/gmt/v4/原神博士/原神博士_e10_s140_l32.pth. _IncompatibleKeys(missing_keys=['enc_p.ssl_proj.weight', 'enc_p.ssl_proj.bias', ....])
2025-09-17 14:34:33.648 | INFO 14272 cache.py:67 - {'v4': {'last_used': '2025-09-17 14:34:33', 'usage': 1},'v4-原神博士-默认': {'last_used': '2025-09-17 14:36:25', 'usage': 1}}
2025-09-17 14:34:33.649 | INFO 14272 TTS.py:197 - Set seed to 99578076
2025-09-17 14:34:33.652 | INFO 14272 TTS.py:1046 - Parallel Inference Mode Enabled
2025-09-17 14:34:33.652 | INFO 14272 TTS.py:1064 - When parallel inference mode is enabled, SoVITS V3/4 models do not support bucket processing; bucket processing has been automatically disabled.
2025-09-17 14:34:34.676 | INFO 14272 TTS.py:1118 - Actual Input Reference Text:
2025-09-17 14:34:35.826 | INFO 14272 TextPreprocessor.py:61 - ############ Segment Text ############
2025-09-17 14:34:35.827 | INFO 14272 TextPreprocessor.py:84 - Actual Input Target Text:
2025-09-17 14:34:35.827 | INFO 14272 TextPreprocessor.py:85 - CreatorBox,为创作者而生,提升创作效率,释放创作潜力.
2025-09-17 14:34:35.828 | INFO 14272 TextPreprocessor.py:114 - Actual Input Target Text (after sentence segmentation):
2025-09-17 14:34:35.829 | INFO 14272 TextPreprocessor.py:115 - ['CreatorBox,', '为创作者而生,', '提升创作效率,', '释放创作潜力.']
2025-09-17 14:34:35.829 | INFO 14272 TextPreprocessor.py:65 - ############ Extract Text BERT Features ############
<!-- 并行处理,省略 -->
2025-09-17 14:34:40.471 | INFO 14272 TTS.py:1187 - ############ Inference ############
2025-09-17 14:34:40.471 | INFO 14272 TTS.py:1209 - Processed text from the frontend (per sentence):
2025-09-17 14:34:40.471 | INFO 14272 TTS.py:1217 - ############ Predict Semantic Token ############
2%|████ | 29/1500 [00:00<00:19, 75.04it/s]T2S Decoding EOS [141 -> 176]
2%|████▊ | 34/1500 [00:00<00:21, 68.26it/s]
<!-- ..... -->
2025-09-17 14:35:50.402 | INFO 14272 TTS.py:1258 - ############ Synthesize Audio ############
2025-09-17 14:35:50.402 | INFO 14272 TTS.py:1305 - Parallel Synthesis in Progress...
2025-09-17 14:36:18.686 | INFO 14272 TTS.py:1342 - 2.173 4.645 2.194 96.021
2025-09-17 14:36:18.688 | INFO 14272 gptsovits_tts.py:195 - speech len 6.96, rtf 15.091852826633673
2025-09-17 14:36:18.864 | INFO 14272 response.py:52 - {"path":"webapp/tts/sovits_zh-CN_原神博士_1.00_1.00_1.00_32_0.wav","duration":6.96,"seed":99578076}