Language Translation 🌐
Translate between multiple languages, allowing you to switch translation providers and adjust advanced parameters to optimize translation results, easily overcoming language barriers.
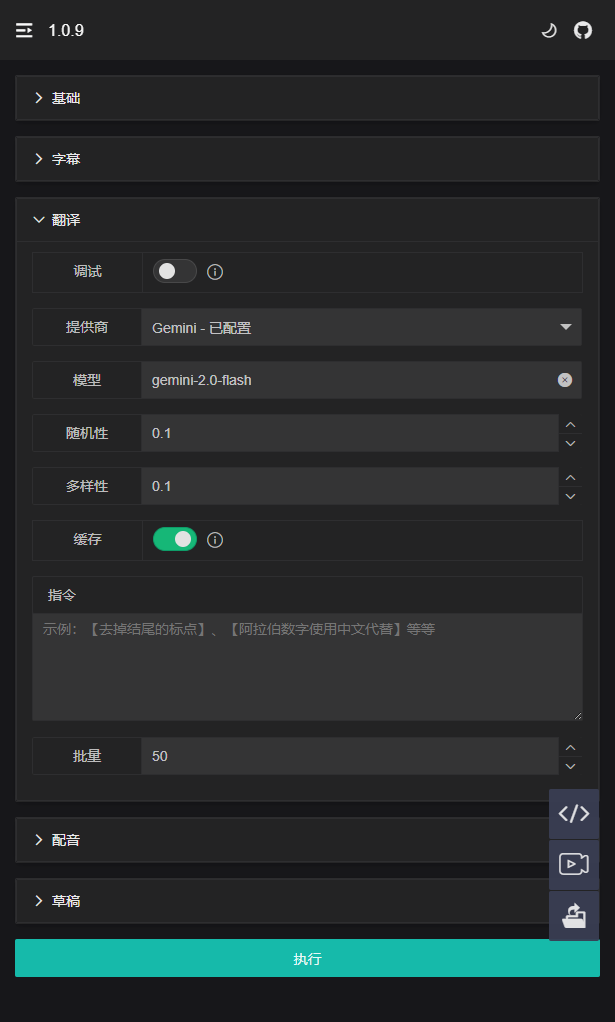
Debug Mode
After subtitle recognition is complete, click Execute to start. At this point, when Debug Mode is enabled, subsequent execution will be interrupted.
2025-04-11 01:12:30.420 | INFO 12868 response.py:28 - {"task_id":"806c875f7d89405c91318515fafffa3ee"}
2025-04-11 01:12:30.422 | INFO 12868 cbutils.py:310 - File already exists. webapp/temp/test/test.mp4
2025-04-11 01:12:30.426 | INFO 12868 cbaudio.py:59 - Audio extracted and saved to: webapp/temp/test/test.wav duration 30.570666666666668s
2025-04-11 01:12:30.426 | INFO 12868 spleeter_.py:73 - Audio separate file already exists. (webapp/temp/test/stems/test_vocals.wav , webapp/temp/test/stems/test_vocals_bg.wav)
2025-04-11 01:12:34.485 | INFO 12868 trans_.py:39 - {'provider': 'Gemini', 'model': 'gemini-2.0-flash', 'json_path': 'webapp/temp/test/test_001.json', 'language': 'zh-CN', 'kwargs': {'temperature': 0.1, 'top_p': 0.1, 'cache': True, 'debug': True}}
2025-04-11 01:12:34.486 | INFO 12868 trans_.py:41 - language: zh-CN
2025-04-11 01:12:34.487 | INFO 12868 llm.py:43 - {'provider': 'Gemini', 'model': 'gemini-2.0-flash', 'kwargs': {'temperature': 0.1, 'top_p': 0.1, 'cache': True}}
2025-04-11 01:12:35.519 | INFO 12868 llm.py:81 - LLM provider Gemini model gemini-2.0-flash
2025-04-11 01:12:35.527 | INFO 12868 llm.py:115 - cache miss prompt md5(c71541dbcc2e1911bfe99377113cbb3a)...
2025-04-11 01:12:36.129 | INFO 10992 task.py:34 - current time: 2025-04-11 01:12:36.129094
2025-04-11 01:12:38.237 | INFO 12868 llm.py:119 - cache update for prompt md5(c71541dbcc2e1911bfe99377113cbb3a) ...
2025-04-11 01:12:38.252 | INFO 12868 llm.py:92 - Gemini token usage: input tokens: 475, output tokens: 370, total tokens: 845
2025-04-11 01:12:38.587 | INFO 12868 trans_.py:71 - Translated transcription:
Hello everyone. You may not have seen these amazing gadgets. Many people don't even know they exist. Today, I will show you six amazing egg cooking tools. This rolling egg storage box is perfect for organizing eggs. It's narrow and doesn't take up refrigerator space. It can hold 15 eggs. The quality and workmanship of this rack are excellent, and it fits perfectly on the side of the refrigerator. Every time you take the top one, the eggs below will automatically roll down, which is very convenient. This...
2025-04-11 01:12:38.588 | INFO 12868 trans_.py:79 - Translated data complete and saved to: webapp/temp/test/test_001.jsonView Content
By clicking the bottom-right icon , you can view the currently recognized content.
Manual Modification
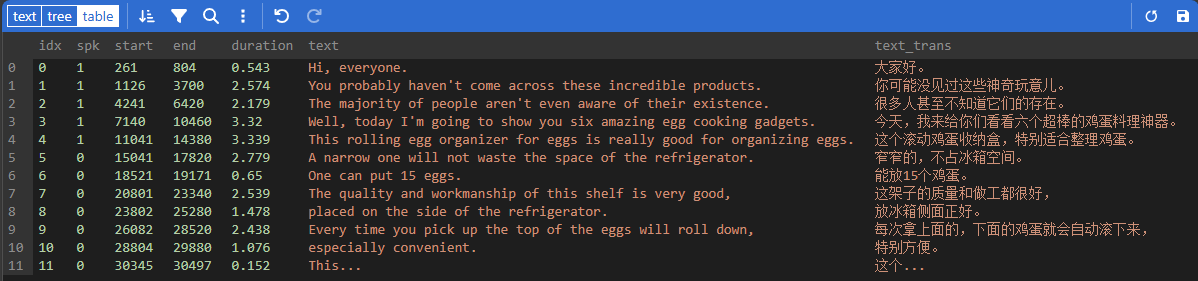
Modify the text values of different attributes and click the top-right icon to save the changes.
Provider Selection
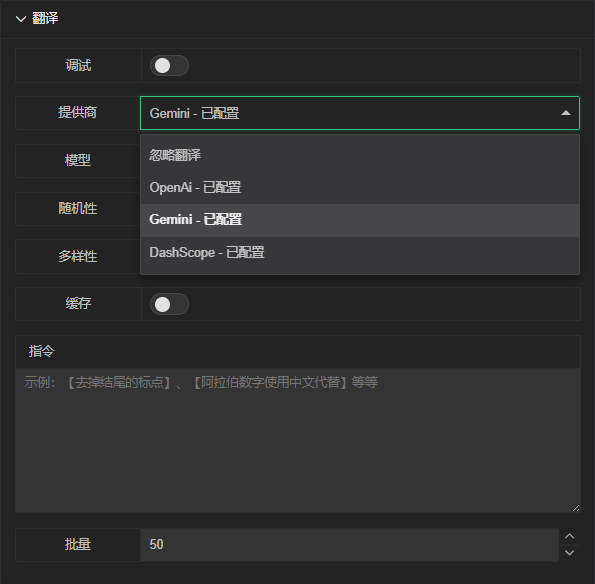
Description
[
"OpenAi", // OpenAi's large language model
"Gemini", // Google's large language model
]| Provider | Environment Variable | VPN Required | Recommendation |
|---|---|---|---|
| OpenAi | OPENAI_API_KEY | ✅ | 🔥🔥🔥🔥🔥 |
| Gemini | GOOGLE_API_KEY | ✅ | 🔥🔥🔥🔥🔥 |
Configuration
OpenAi
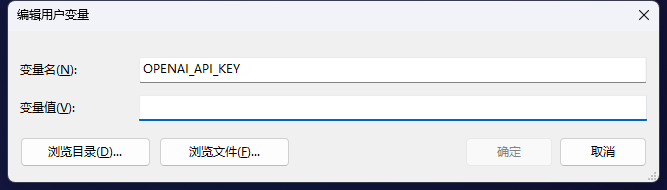
Gemini
TIP
- Environment variable configuration can be found in the 《Preparation》 section.
- It is recommended to choose the appropriate
providerandmodelbased on actual needs.
Configuration Options
Model
Each provider has a corresponding default model, and users can also customize it.
| Provider | Default Value | Options |
|---|---|---|
| Ignore | - | - |
| OpenAi | gpt-3.5-turbo | gpt-3.5-turbo、gpt-4-turbo、o4-mini、o3-mini more |
| Gemini | gemini-2.0-flash | gemini-2.5-pro、gemini-2.5-flash、gemini-1.5-pro、gemini-1.5-flash more |
What is the purpose of the Ignore option?
Through
debugging, we know the returned translation results, but there are always some translations that need manual adjustment. At this point, we can individually modify thetext_transvalue and save it.In subsequent executions, if we want to use our manually adjusted translation, we can select the
Ignoreoption.
Randomness
Controls the randomness of text generation. Lower temperature is more accurate, while higher temperature is more creative.
Diversity
Controls the depth of exploration during generation. Larger values usually generate more accurate text.
Batch Processing
Controls the length of returned content, processing long texts in batches.
Cache
When enabled, it can save token usage by prioritizing reading from the cache.
xxx_001.json All text values within the same batch are processed in a single request.
2025-04-11 03:19:26.825 | INFO 5636 llm.py:81 - LLM provider Gemini model gemini-2.0-flash
2025-04-11 03:18:40.892 | INFO 5636 llm.py:115 - cache miss prompt md5(c71541dbcc2e1911bfe99377113cbb3a)...
2025-04-11 03:19:26.829 | INFO 5636 llm.py:113 - cache hit prompt md5(c71541dbcc2e1911bfe99377113cbb3a)...
2025-04-11 03:19:26.831 | INFO 5636 llm.py:92 - Gemini token usage: input tokens: 475, output tokens: 370, total tokens: 845Instructions
User input instructions will be part of the template instructions.
prompt = TemplatePrompt(
template="""
You are a translation expert. Based on the information I provide, complete the following content:
Goal:
Translate into {language}
Requirements:
{instruct}
Content:
{text}
Please strictly follow the JSON Schema below to return results:
{schema}
Example:
{example}
""",
)